Performance comparison between TF-IDF and Word2Vec
- 2023년 9월 19일
- 5분 분량

Performance comparison between TF-IDF and Word2Vec
In this experiment, an initial condition experiment of TF-IDF and Word2Vec was conducted to construct ESG keywords based on KCGS' ESG best practices. To evaluate the results, similarity analysis was employed between KCGS's ESG standards, which serve as the reference set, and the ESG keywords derived for each model. <Figure 2> illustrates the similarity between ESG keywords using the TF-IDF algorithm and the actual correct answers.
In the initial conditions without parameter tuning, the environmental field (E) yielded a score of 0.474, the social field (S) scored 0.577, and the governance (G) had a score of 0.439. TF-IDF calculated higher weights for words that appeared in subordinate positions, leading to the presentation of special words and minority phrases as topic words. In other words, it can be observed that TF-IDF tends to assign high importance to topic words occurring in subset documents when the quantity of documents is limited. <Figure 3> illustrates the similarity in the initial state without parameter tuning using the Word2Vec algorithm. The environmental field (E) achieved a similarity score of 0.694, the social field (S) scored 0.676, and the governance (G) scored 0.622. This suggests that Word2Vec selected more sophisticated keywords compared to TF-IDF.

<Figure 2> Results of similarity analysis for TF-IDF

<Figure 3> Results of similarity analysis for W2V
The reasons why the Word2Vec algorithm displayed a high similarity value in this experiment are as follows. In the case of the Word2Vec algorithm, when extracting topic words, it constructs words related to the topics, resulting in the removal of certain minor phrases or unnecessary words. Furthermore, it was observed that the extraction of semantic keywords involved eliminating words that deviate from the topic and retaining words from major groups. However, with the Word2Vec algorithm, if the word frequency threshold is altered or the experimental parameters within the algorithm are modified, the keywords can change accordingly(Moon and Lee, 2022). Therefore, the Word2Vec algorithm requires adjustment of hyperparameters, and optimization change experiments enhance context information to determine the final ESG keywords.
Hyperparameter optimization experiment of Word2Vec
When the Word2Vec model is employed for text classification, parameter adjustment may not be as critical, but hyperparameter experiments become essential when subject words are derived from independent morphemes. The key hyperparameter factors that impact the model are typically recognized as the minimum frequency of occurrence, learning dimension vector size, window size, and the number of learning iterations(Goldberg and Levy, 2014).
When comparing previous studies on optimizing parameters using the Word2Vec model, there hasn't been sufficient evidence to define hyperparameters with specific variables. For instance, in the case of Korean, researchers have suggested that 50 or 100 dimensions are suitable for the dimensional vector size in the learning algorithm, while experimental cases have demonstrated excellent similarity in dimensions of 300 or more(Kang and Yang, 2019). Some research has indicated that using at least two window sizes from the central morpheme enhances performance, and that optimization is achieved with a window size of 30(Choi, Sul and Lee, 2016). Therefore, in this study, it would be appropriate to select the variable whose result value reaches the maximum through repeated parameter experiments.
<Figure 4> to <Figure 6> present the experimental results of the minimum frequency of occurrence (3, 5, 10, 15, 30), which is a parameter of Word2Vec, and the size of the learning algorithm dimension vector (100, 300, 500, 700).
Common characteristics observed in <Figure 4>, <Figure 5>, and <Figure 6> are as follows: When the minimum frequency of a word is low, the similarity evaluation result shows a low value, and as the minimum frequency of occurrence increases, the similarity becomes higher. This conclusion aligns with existing research results, which suggest that an increase in the minimum frequency of appearance has a positive effect on similarity. When it comes to the learning dimension vector size, the value of the similarity result neither increases nor decreases significantly. When the frequency of occurrence is low, proper learning doesn't take place, and biases can emerge. Therefore, it's essential to explore appropriate numerical values for the minimum frequency through parameter experiments. However, it's evident that the size of the learning dimension vector doesn't have a significant impact.
In the environmental field (<Figure 4>), the minimum frequency of occurrence is 15, and the similarity reaches its highest level at 0.741. The reason for the high similarity value, despite the lower minimum frequency of occurrence compared to other fields, is the clear visibility of context between words. Therefore, it can be inferred that in the environmental field, normative information is composed of a clearly defined context. In the social field (<Figure 5>), when the minimum frequency of occurrence was set to 30, the maximum similarity reached 0.893. In the governance structure (<Figure 6>), with a minimum frequency of appearance set at 30, the similarity reaches its maximum at 0.806.

<Figure 4> Optimization result of similarity between frequency and Vec dimension (E)

<Figure 5> Optimization result of similarity between frequency and Vec dimension (S)
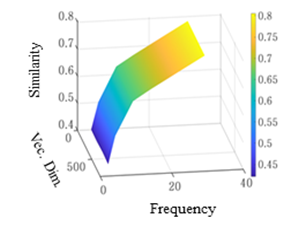
<Figure 6> Optimization result of similarity between frequency and Vec dimension (G)
In <Figure 7>, <Figure 8>, and <Figure 9>, the minimum frequency of occurrence and the learning dimension vector size are fixed, and the window size (5, 10, 30, 50) and number of repetitions (10, 20, 30) parameters are set. This is the result of an experiment. In <Figure 7> for the environmental field (E), <Figure 8> for the social field (S), and <Figure 9> for governance (G), the similarity increases as the window size increases, reaching its maximum at 30. It appears to have reached optimization. Therefore, the experimental results align with the same conclusion as the previous study, which suggested a positive effect when the window size was set to 30 or more. After reaching the maximum value, increasing the window size resulted in a slight decrease in accuracy.
In <Figure 7>, in the case of the environmental field (E), the similarity reaches its maximum value of 0.741 when the number of repetitions is 30. In the case of social field (S) in <Figure 8> and governance (G) in <Figure 9>, the maximum values were 0.893 and 0.806, respectively, respectively, when the number of repetitions was set at 20. The parameter was also 20 when the number of repetitions was 30, resulting in the same value. In general, as the number of repetitions In general, as the number of repetitions increases, accuracy performance improves, but it reaches a point where further improvement is limited due to the size or content of the text(Kang and Yang, 2019; Kim and Koo, 2017). At this critical point, performance converges. Therefore, it appears appropriate to select the parameter that converges to the maximum value by identifying the minimum number of learning repetitions.



IN this experiment, the Skip-Gram (SG) method, known for its excellent performance in the Word2Vec architecture, served as the basic model, and the optimal parameter results are as follows. When the word frequency is too low, effective learning doesn't occur, leading to bias. Therefore, the minimum frequency of occurrence was set to 15 or more, and the window size reached its maximum value at 30, aligning with the conclusions of previous studies. Performance no longer improved and converged when the number of iterations reached 20. In this experiment, the size of the learning dimension vector did not appear to have a significant impact on determining the keywords. Similar to existing experimental results, setting it to 100 dimensions was found to be an appropriate parameter setting for keyword analysis(Al-Saqqa and Awajan, 2019; Ma & Zhang, 2015; Mikolov et al., 2013). Although the optimization parameters of the Word2Vec algorithm may vary depending on the text, the results of this experiment align with the parameters presented in previous studies, reaffirming the parameters that ensure numerical validity.




댓글